A Proactive Strategy for Control System Maintenance

It’s long been known that a reactive approach to industrial control system maintenance is not an ideal strategy. Working from a reactive stance, in which problems are corrected as they occur, results in unplanned downtimes, lost production costs, as well as potentially higher repair costs as problems are not detected early enough to avoid additional impacts.
Moving to a proactive strategy, however, requires technology that can provide insights into control systems and their performance to alert users to the fact that specific maintenance or repairs are needed to keep the system in working order.
To learn more about how industrial companies are moving from reactive to proactive maintenance strategies, we connected with Bart Winters of Honeywell Process Solutions for a recent episode of the “Automation World Gets Your Questions Answered” podcast series.
Proactive vs. reactive
Beginning our discussion with a focus on the differences between reactive and proactive maintenance strategies for industrial control system maintenance strategies, Winters said that the similarities between plant equipment like pumps and compressors, as well as the control system, help make the move from reactive to proactive easier. In essence, what this move in strategies is all about is “not waiting for a problem with a piece of the equipment on your control system—whether it's an I/O card or a network issue—to manifest itself and then you have to go fix that problem,” he said. “Now we're able to pick up leading indicators to detect that there's a condition that might be causing a problem and be able to respond to that proactively or in advance [of a failure] to prevent the emergency or the unplanned outage.”

The digital connection
Winters said that Honeywell thinks about proactive support and maintenance as part of the “digital transformation or a digital execution model, where we are in a position to collect the data, check the data, make sure it's within the recommended settings or ranges, and be able to respond to those conditions in advance.”
We are uploading the site data, performance data, health data, and configuration and [system] inventory information into a cloud-hosted environment where we continuously check the health of the control system in terms of performance parameters and we communicate that to the customer.
The control system scope addressed by Honeywell’s approach to proactive maintenance looks at a company’s control system from an I/O health and network performance perspective, as well as the controllers, the HMI/SCADA system, and/or the distributed control system. “It’s basically the whole operational technology layer for maintaining the health of that system,” Winters said.
Proactive maintenance benefits
Whether its for control system maintenance or general plant equipment maintenance, Winters said, “We see that emergency or reactive work is 10 times more expensive than planned or proactive maintenance. With a proactive or a planned maintenance strategy, the time spent to both correct the problem, as well as the prevention of the loss downtime, is about relieving people's time spent looking for problems [and giving them time] to spend on solving problems.”
Describing how Honeywell has evolved in how it helps users move toward proactive maintenance, Winters said, in the past, Honeywell provided what it called an “automation system assessment”—a periodic assessment in which Honeywell would perform several checks on a control system and then generate a report for the customer spotlighting the issues detected that require attention.
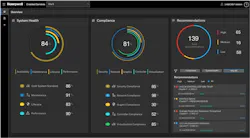
Winters explained that Enabled Services is a service level offering from Honeywell for its control systems. With this service, “we are uploading the site data, performance data, health data, and configuration and [system] inventory information into a cloud-hosted environment where we continuously check the health of the control system in terms of performance parameters and we communicate that to the customer,” he said. “We're looking at your patching level and software versioning, as well as the configuration of your control system to make sure it's within the specified recommended best practices for how the system is actually configured to ensure it's operating properly. By doing this, we reduce the risk or likelihood of loss of control, or a loss of view event that could potentially cause a plant shut down.”
Safety connections
In our discussion, Winters noted that following the digital execution model provides specific insights from the DCS (distributed control system) related to worker safety. He said Honeywell has seen several industry studies that correlate worker safety or plant safety to higher reliability levels. The reason for this is that the ability to better plan maintenance often translates into fewer mistakes being made versus reacting in an emergency or an upset situation when the plant is down and you may have lost control or lost your view of the process.
“In that case, you’re hurrying up and trying to do things that might end up causing other problems, such as reboot the wrong server or replace the wrong I/O card,” he said. “And if you're starting up from a shutdown situation, we know that steady state operations are a lot more stable and safer than doing plant startups.”
About the Author


Leaders relevant to this article: