Data Analysis: At the Edge or in the Cloud?
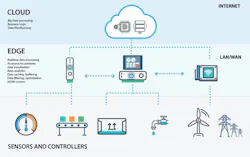
Once the decision has been made to perform ongoing analysis of the current and historical data generated by your production assets, the analytics decision-making process has only just begun. Your biggest decisions remain ahead, and revolve around where and how to best conduct those analytics.
As more companies pursue data analytics, it’s become clear that hybrid applications are seen as the optimal choice. The term hybrid, in this instance, refers to a combination of analytics performed by both edge and cloud computing platforms. Results from a recent Automation World survey—conducted for an October 2018 feature on edge, cloud and fog computing use—reveal that 43 percent of respondents are currently using edge computing implementations and 51 percent are using cloud computing. Responses to the survey indicate a not-insignificant level of hybrid cloud/edge applications.
But understanding the use of hybrid analytic models only answers part of the analytics architecture question. Users still need to determine how to most effectively conduct their data analysis. In other words: In a hybrid edge/cloud analytic environment, what kinds of data should get sent to the cloud and what should be analyzed at the edge?
To get more insight into this question, I spoke with Chris Nelson, vice president of engineering at OSIsoft, a company long recognized for its expertise in plant data analytics. To help make the best determination of the line dividing what data should go the cloud for analysis and what should be analyzed at the edge, we evaluated five factors: speed, reliability, safety, bandwidth and complexity.
Speed
Like any complex question, the question of how speed factors into the cloud versus edge data analysis determination is answered by: It depends. The reason the answer cannot be clearly delineated is that there is no standard or clear cutoff for this decision.
Beyond the obvious issues of bandwidth cost and quality of connection, Nelson said the amount and type of data involved, as well as the time you have to solve the problem, all come into play.
When considering the amount and type of data to analyze, Nelson said two initial questions arise: Does it make sense to store it at the edge or not? Does this decision need to be made in minutes or could it be reviewed for a week or two?
To clarify, Nelson said, “Most predictive maintenance problems can be solved at the edge. If an engineer or operator sees a sudden change in performance, he or she can often quickly narrow it down to a few causes. The analytics, in that case, are really being supplied by your employee. But let’s say it’s a hugely complex problem, like determining why a particular factory is more efficient than the other ones and whether or not the practices in that facility can help reduce the capital spend for the next decade. Then you’re talking about a gargantuan math problem that’s better solved by running multiple scenarios in the cloud. So the demarcation line is really whether you’re looking at a human-scale problem or whether you need algorithms to really solve the problem.”
Reliability and safety
Though these two issues are clearly distinct, they are also clearly interwoven and demand an immediate response. The need for a fast response makes edge computed analysis the obvious choice. But cloud computing can still play a role here.
“Shell, for instance, has created a system to monitor the performance and health of its blow out preventers in real time at a control desk,” Nelson noted as an example of an edge computing application in this area. “If there is a sudden surge or problem, it can cap the well immediately. With this system, Shell can see real-time performance as well as study performance over time. Likewise, quality and product safety in food, pharma and water are classic edge computing problems. If something is going wrong with the production of a pharmaceutical—let’s say the process is deviating because of environmental factors or a change in the mixture of materials—you want to know immediately. You can halt production, fix the issue and prevent what could be a costly and complex recall.”
The cloud can play a role in reliability and safety issues when it comes to long-term diagnostics, said Nelson. “For example, is there something in your system causing a recurring problem that could be changed to fix that issue on a permanent basis?”
Bandwidth
“Bandwidth quality is an issue for remote assets, and its associated costs are a huge issue,” said Nelson. “Think of a wind farm. There are roughly 650 parameters you might want to monitor on a wind turbine. If you pinged these every ten minutes, that’s 93,000 a day. And that’s just one turbine. There are wind farms with a few hundred. In fact, in the U.S. there are over 57,000 turbines. Your connectivity bill would be outrageous because you’re sending a lot of data to the cloud and most of that data only needs to be used locally. A better strategy—and one we see companies adopting—is to store the data locally and send snapshots to the cloud.”
Nelson noted that some companies are using LTE to mitigate the cost issue of sending large amounts of data to the cloud. “Sempra Energy recently rolled out an experimental LTE network with Nokia and OSIsoft in the Broken Bow II wind farm in Nebraska,” he said. “If one of the pitch bearing units goes, it can cost $150,000. With OSIsoft’s PI System data and LTE, Sempra can detect the problem before it fully blossoms and fix it for up to 90 percent less.”
Complexity
Determining the complexity factor that would mark the dividing line between cloud and edge use is, not surprisingly, a complex consideration. To help clarify, Nelson offered a few examples.
In his first example, he referred to MOL, a large oil refiner based in Hungary. “Overall, they track around 400,000 data streams or tags with the PI System. At one point MOL was experiencing a high temperature hydrogen attack. Essentially, that’s when loose hydrogen molecules in a reactor get embedded into the steel walls and start to weaken them. Engineers saw the corrosion, suspected it might be a hydrogen issue and confirmed it with PI data. They also used the system to track the progress of the fix. They were able to roll it out to six units within a week. When that trial succeeded, they rolled it to 50 units. This was an example of engineers using PI to solve the problem locally—at the edge—and then replicate it. Later, MOL came up with the idea of using higher sulfur opportunity crudes in its system. This had the potential to create problems because MOL’s production line was designed for higher grade crudes. Determining whether or not to use opportunity crudes, however, is a titanic math problem involving different simulations and scenarios. How will the daily volume change? Will this increase wear and tear and therefore maintenance costs? What happens if overall market prices dip? To address these questions, MOL took PI System data at the edge and shuttled it to Microsoft Azure. This analysis program is underway.”
For a second example, Nelson referenced a problem Deschutes Brewery was having with one of its beers being over-fermented. “By using the PI System and an additional sensor, it basically found a zone in the tank where the yeast was too active. A fix was installed that also reduced brewing time, allowing Deschutes to produce roughly $400,000 worth of additional beer on the same line.” This is an example of an edge computing analytics application that improved production for the brewery.
Following this success, Deschutes then wanted to study the fermentation cycle of each beer. They wanted to know things like: At what point does its Fresh Squeezed IPA hit a specific alcohol content and how is that different from its Black Butte Porter? “That’s a math problem better solved in Azure,” said Nelson.
To help summarize the edge/cloud analysis dividing line question, Nelson suggested approaching the issue this way: “If the problem is something users could solve on their own with good sources of information, focus the analysis at the edge. If you’re talking about 15 different data streams and multiple variables, it’s a problem better suited for the cloud.”

