Fault-Tolerant Platforms for Manufacturing Application Protection
Though Automation World most often focuses its coverage on plant floor applications of automation technology, protecting the software applications that operate and control much of that shop floor automation is a critical requirement of modern manufacturing. And while no one ignores these applications, the strategies used to protect them can be questionable in some cases.
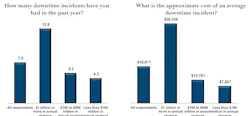
To illustrate my point, a recent survey by Stratus of manufacturers across a range of industries, showed that 30 percent of manufacturers experienced downtime for one or more applications in the first four months of 2013. More worrisome is that the average number of downtime incidents has gone up considerably from 2012 to 2013 — from four to seven — at a cost of about $17,000 per incident, according to Stratus.
As to why incidents of unplanned downtime might be on the rise, Stratus says its study indicates that only one in three respondents have a high-availability manufacturing IT strategy in place. Of those manufacturers that do, 66 percent rely on traditional backup for maintaining system reliability and uptime.
“While backup is an important best practice for ensuring that applications and data can be restored in the event of human error, power outages, hardware failures, or natural disasters, it’s simply not a reliable high-availability strategy for ‘always-on’ manufacturing environments,” says Frank Hill, director of manufacturing business development for Stratus Technologies. “Restoring applications and data from backup is a long manual process that can take hours or even days to complete. In the meantime, equipment is idle, customer orders are delayed, and lost productivity costs eat into already tight profit margins.”
Rather than using traditional back up systems, a smaller but still significant percentage of manufacturers are using built-in high-availability functions (26 percent) or clustering (19 percent) to minimize unplanned downtime, according to Stratus. Though these approaches are more effective than traditional backup for achieving high availability, Hill says these methods are still not ideal because they focus on recovering from system outages rather than preventing them.
“Built-in availability functions and clustering solutions rely on complex ‘failure recovery’ mechanisms that incur varying degrees of downtime,” Hill says. “During these failover/recovery periods, which can range from a few seconds to minutes, a backup system automatically restarts the applications and logs on users. This failover process can degrade performance, compromise throughput, and result in the loss of ‘in-flight’ data.”
Clusters are built from combinations of conventional servers, software and enabling technologies, and require vigilant administrative oversight by specialized IT professionals, Hill says. “They require failover scripting and testing that must be repeated whenever changes are made to the environment. In addition, they may require licensing and installation of multiple copies of software, as well as software upgrades and application modifications. Some clustering solutions even require external shared storage, which adds more cost and complexity.”
It’s no surprise that Stratus has recommendations on how to remedy this situation, given that it is a supplier of IT infrastructures to ensure uptime, but it’s recommendations are worth considering regardless of whom you work with to provide your system infrastructure support.
According to Hill, the best way to ensure continuous availability of critical manufacturing applications is to adopt a strategy that prevents downtime from happening in the first place, rather than just recovering from downtime once it has occurred. Hill recommends using high-availability software solutions with built-in fault-tolerance. This strategy “combines the physical resources of two standard servers into a single operating environment with complete redundancy of all underlying hardware and data to prevent unplanned downtime and keep applications running, even in the event of component or system failures,” Hill adds, noting that this approach creates an application environment that delivers “availability levels of 99.995% or more.”
Unlike many availability solutions that focus on failover and recovery, Hill says that fault-tolerant servers are designed to “detect, isolate, and correct system problems before they cause costly system downtime or data loss.”
These high-availability fault-tolerant systems do this through use of a “lockstep architecture that simultaneously processes work instructions and synchronizes memory in two separate hardware components so the user experiences no interruption to operations even if a component fails. These systems’ built-in 24/7 support technologies monitor hundreds of critical conditions, enabling proactive resolution of issues before they impact system performance or availability. The result is uninterrupted operations with downtime of less than 30 seconds per month, on average."
The obvious question at this point is: If these high availability, fault-tolerant systems are so great, why aren't more manufacturers using them? Hill says it’s due in part to the misconception that these systems are too expensive.
The reality is that high-availability fault-tolerant software solutions can be more cost effective and easier to deploy and manage than alternative solutions. Hill says, “Some high-availability software offerings run on standard x86 servers that most organizations already have in place within their computing infrastructure. These solutions offer operational simplicity, allowing your existing applications to run without the risk and expense of modifications that could negatively affect applications that may not have been altered in years. In addition, they deliver availability levels that exceed those offered by clusters.”
Hill adds that fault-tolerant platform systems provide total cost of ownership advantages. For example, Hill points out that these systems include replicated hardware components — CPUs, chipsets, and memory — so you don’t need to pay for a second server, another copy of the operating system, duplicate application licenses, redundant switches, and external storage. Plus, a simpler configuration with fewer components means lower costs — both upfront and throughout the system lifecycle. Add in the money you save by avoiding the staggering cost of unplanned downtime and you can see why some manufacturers have realized payback from their fault-tolerant platforms in as little as nine months.”
As you look to improve your uptime and protect your manufacturing applications, it may make sense to consider the use of high-availability, fault-tolerant systems.
About the Author


Leaders relevant to this article: